

Wendy Robertson, Digital Scholarship Librarian at University of Iowa, recently wrote a great blog when the New York Times picked up the newly discovered Walt Whitman work just published in University of Iowa’s repository in the Walt Whitman Quarterly Review. We are reprinting it below so the Digital Commons community can follow her journey to the dizzying heights of this impact story, rooted in a journal that went open access last year. Enjoy!
When content goes viral: looking at the first 3 days of “Manly Health and Training”
By Wendy Robertson
May 3, 2016
On Friday, the Walt Whitman Quarterly Review (WWQR) published a previously unknown book-length work “Manly Health and Training,” by Walt Whitman, recently discovered by Zachary Turpin. (Read more about it in a previous post.) Minutes after it was published, The New York Times broke the story. (We couldn’t say anything until their story launched at about 10am, and the editors carefully timed publication to be minutes before the announcement.) From that point forward, we watched as the downloads of the content climbed. And yes, for some of us, this included watching over the weekend because it was very exciting!
The use was obviously high for the journal itself, but the use for our entire repository was massively spiked by this publication; over 91% of the traffic on our entire repository was for Walt Whitman Quarterly Review. This illustrates the typical use of our site from April 1–May 2WWQR. 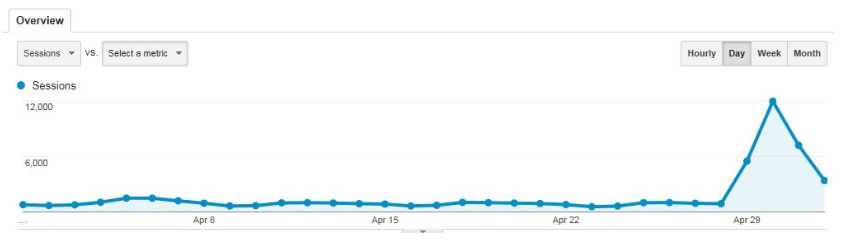
While the other items in the journal issue did not receive nearly as much use as the Whitman work and the introduction about the work, they received far more use than would be typical. Compare the first 3 days of use for a book review, bibliography, and back matter in this issue with similar items in the previous issue since being published.
Downloads of current issue (29 April–1 May 2016)

Downloads of previous issue (31 Dec 2015–2 May 2016)

People all over the world downloaded this newly discovered Whitman work. The first image shows downloads of in Walt Whitman Quarterly Review vol 33 issue 3 during the first three days when “Manly Health and Training” was published.
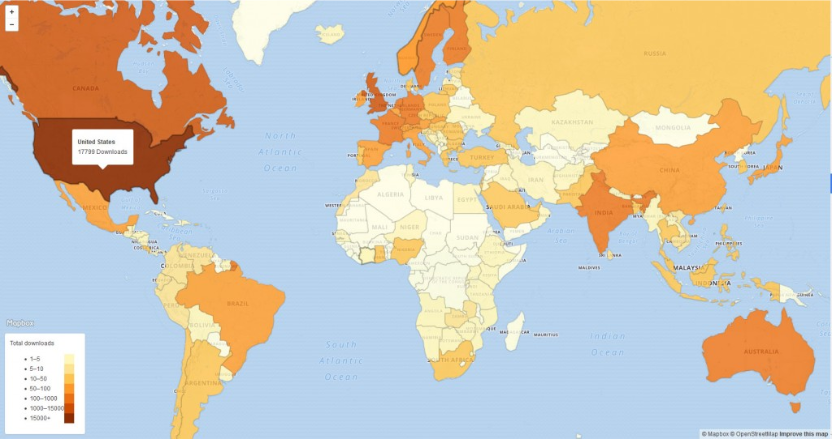
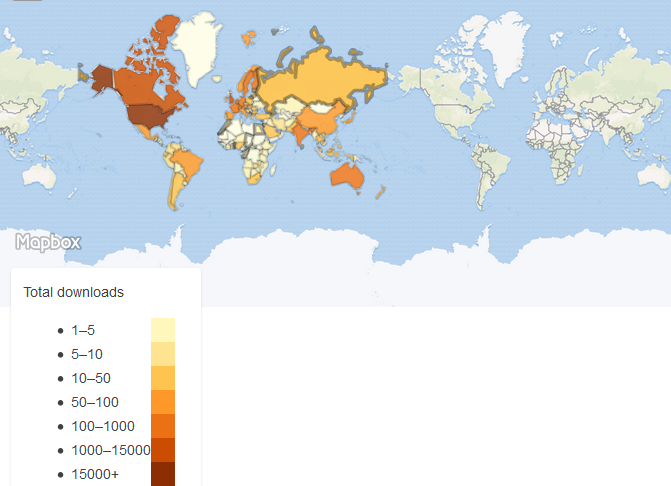
This second map is interactive [click on map for link to blog site where map is interactive] so you can see the counts by country. We will also periodically update this map with more recent data.
Most people who downloaded the content first went the journal or issue site (10,826 out of 18,234), so it is impossible to know what articles and posts resulted in the most downloads. The numbers below reflect the downloads that occurred when users were coming directly from another publication (i.e. a link to the PDF). I think these numbers are not included in the Google analytics counts because links directly to our PDFs do not appear in Google Analytics.

Google Analytics shows us what sites directed traffic to our site, but do not indicate if people downloaded content. Historically, most of the downloads on our site come from Google (and other search engines). During this 3 day period, traffic to WWQR was largely from all the news sources that had articles. People arrived at the specific issue or the WWQR site as a whole largely from links on referring sites (15,191). Only 584 (of the 22,387 total sessions) came via a search engine. It is unclear where 6,480 sessions originated as the links appear to be direct. This could be links from email, it might be people who have turned tracking off, or it may be people typing in the URL directly.
The top referring sites were:
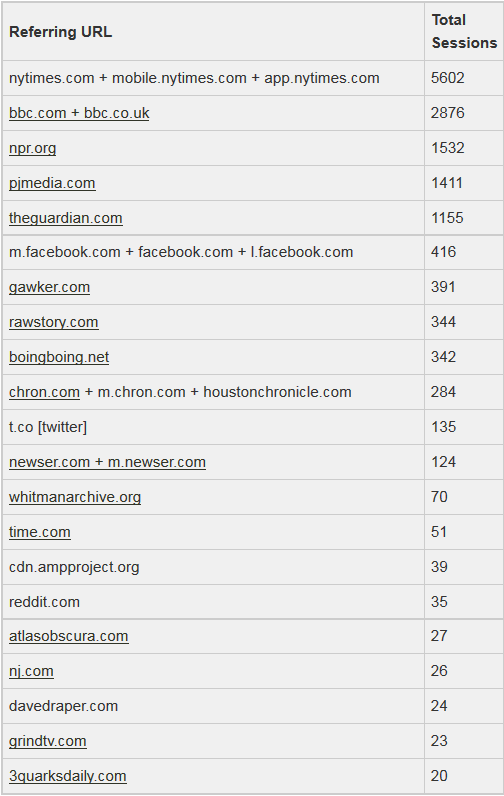
For more media coverage of the discovery and its publication, follow Stephanie Blalock on Twitter (@StephMBlalock), and for information about articles published in each new issue of WWQR, follow the journal (@WaltWhitmanQR).
As more news sources pick up on this, we will post updates about the usage.