

Demonstrable, accurate, up-to-the-minute data about your institution’s scholarly impact is more important than ever. It’s also never been more challenging.
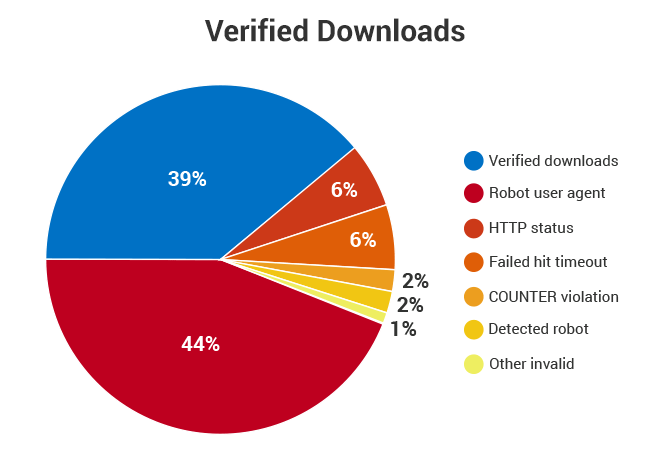
Only 39% of downloads are verified human activity.
Just like not all bacteria are “bad” (frozen yogurt, anyone?), some non-human activity is beneficial to your online content. For example, Google crawlers are instrumental in maintaining high discoverability through Google’s search engine. But a growing number of increasingly sophisticated agents are inflating download counts for open access material. How inflated? Using our filtering methodology, which is the most stringent in the industry, we end up with about 39 intentional human downloads for every 100 unfiltered or “raw” downloads.
We work with over 500 institutions and have a penchant for building visualization tools fed from live data—so we don’t have the time to pore over last month’s download data and determine, for example, that there’s no way that many people would have read one article about commedia dell’arte and nomadism. So we’ve developed a real-time filtering method that we continue to improve on as we (and those pesky bots) learn and grow.
How do we tell human readers from machines? We could, of course, require logins and passwords, but we think that makes open access a little less open. So we track patterns of human and non-human activities to build an ever-evolving process. We build on existing COUNTER standards, which are designed to eliminate erroneous human usage patterns, to remove machine readers as well. We:
We recently joined the COUNTER working group on robots, and are excited to establish some shared recommendations and best practices together. If you want to get an even deeper dive into what we do, you can also watch a webinar reprisal of our presentation on download filtering at Open Repositories 2016 to learn more about our process. (If you’re having trouble viewing the video, try refreshing your browser or clearing your cache before trying again.)